Table of Contents
Evidence on good forecasting practices from the Good Judgment Project
Published 07 February, 2019; last updated 17 July, 2020
According to experience and data from the Good Judgment Project, the following are associated with successful forecasting, in rough decreasing order of combined importance and confidence:
- Past performance in the same broad domain
- Making more predictions on the same question
- Deliberation time
- Collaboration on teams
- Intelligence
- Domain expertise
- Having taken a one-hour training module on these topics
- ‘Cognitive reflection’ test scores
- ‘Active open-mindedness’
- Aggregation of individual judgments
- Use of precise probabilistic predictions
- Use of ‘the outside view’
- ‘Fermi-izing’
- ‘Bayesian reasoning’
- Practice
Details
1. 1. Process
The Good Judgment Project (GJP) was the winning team in IARPA’s 2011-2015 forecasting tournament. In the tournament, six teams assigned probabilistic answers to hundreds of questions about geopolitical events months to a year in the future. Each competing team used a different method for coming up with their guesses, so the tournament helps us to evaluate different forecasting methods.
The GJP team, led by Philip Tetlock and Barbara Mellers, gathered thousands of online volunteers and had them answer the tournament questions. They then made their official forecasts by aggregating these answers. In the process, the team collected data about the patterns of performance in their volunteers, and experimented with aggregation methods and improvement interventions. For example, they ran an RCT to test the effect of a short training program on forecasting accuracy. They especially focused on identifying and making use of the most successful two percent of forecasters, dubbed ‘superforecasters’.
Tetlock’s book Superforecasting describes this process and Tetlock’s resulting understanding of how to forecast well.
1.2. Correlates of successful forecasting
1.2.1. Past performance
Roughly 70% of the superforecasters maintained their status from one year to the next 1. Across all the forecasters, the correlation between performance in one year and performance in the next year was 0.65 2. These high correlations are particularly impressive because the forecasters were online volunteers; presumably substantial variance year-to-year came from forecasters throttling down their engagement due to fatigue or changing life circumstances 3.
1.2.2. Behavioral and dispositional variables
Table 2 depicts the correlations between measured variables amongst GJP’s volunteers in the first two years of the tournament 4. Each is described in more detail below.
The first column shows the relationship between each variable and standardized Brier score, which is a measure of inaccuracy: higher Brier scores mean less accuracy, so negative correlations are good. “Ravens” is an IQ test; “Del time” is deliberation time, and “teams” is whether or not the forecaster was assigned to a team. “Actively open-minded thinking” is an attempt to measure “the tendency to evaluate arguments and evidence without undue bias from one’s own prior beliefs—and with recognition of the fallibility of one’s judgment.” 5
The authors conducted various statistical analyses to explore the relationships between these variables. They computed a structural equation model to predict a forecaster’s accuracy:
Yellow ovals are latent dispositional variables, yellow rectangles are observed dispositional variables, pink rectangles are experimentally manipulated situational variables, and green rectangles are observed behavioral variables. This model has a multiple correlation of 0.64.6
As these data indicate, domain knowledge, intelligence, active open-mindedness, and working in teams each contribute substantially to accuracy. We can also conclude that effort helps, because deliberation time and number of predictions made per question (“belief updating”) both improved accuracy. Finally, training also helps. This is especially surprising because the training module lasted only an hour and its effects persisted for at least a year. The module included content about probabilistic reasoning, using the outside view, avoiding biases, and more.
1.3. Aggregation algorithms
GJP made their official predictions by aggregating and extremizing the predictions of their volunteers. The aggregation algorithm was elitist, meaning that it weighted more heavily people who were better on various metrics. 7 The extremizing step pushes the aggregated judgment closer to 1 or 0, to make it more confident. The degree to which they extremize depends on how diverse and sophisticated the pool of forecasters is. 8 Whether extremizing is a good idea is still controversial. 9
GJP beat all of the other teams. They consistently beat the control group—which was a forecast made by averaging ordinary forecasters—by more than 60%. 10 They also beat a prediction market inside the intelligence community—populated by professional analysts with access to classified information—by 25-30%. 11
That said, individual superforecasters did almost as well, so the elitism of the algorithm may account for a lot of its success.12
1.4. Outside View
The forecasters who received training were asked to record, for each prediction, which parts of the training they used to make it. Some parts of the training—e.g. “Post-mortem analysis”—were correlated with inaccuracy, but others—most notably “Comparison classes”—were correlated with accuracy. 13 ‘Comparison classes’ is another term for reference-class forecasting, also known as ‘the outside view’. It is the method of assigning a probability by straightforward extrapolation from similar past situations and their outcomes.
1.5. Tetlock’s “Portrait of the modal superforecaster”
This subsection and those that follow will lay out some more qualitative results, things that Tetlock recommends on the basis of his research and interviews with superforecasters. Here is Tetlock’s “portrait of the modal superforecaster:” 14
Philosophic outlook:
- Cautious: Nothing is certain.
- Humble: Reality is infinitely complex.
- Nondeterministic: Whatever happens is not meant to be and does not have to happen.
Abilities & thinking styles:
- Actively open-minded: Beliefs are hypotheses to be tested, not treasures to be protected.
- Intelligent and knowledgeable, with a “Need for Cognition”: Intellectually curious, enjoy puzzles and mental challenges.
- Reflective: Introspective and self-critical
- Numerate: Comfortable with numbers
Methods of forecasting:
- Pragmatic: Not wedded to any idea or agenda
- Analytical: Capable of stepping back from the tip-of-your-nose perspective and considering other views
- Dragonfly-eyed: Value diverse views and synthesize them into their own
- Probabilistic: Judge using many grades of maybe
- Thoughtful updaters: When facts change, they change their minds
- Good intuitive psychologists: Aware of the value of checking thinking for cognitive and emotional biases 15
Work ethic:
- Growth mindset: Believe it’s possible to get better
- Grit: Determined to keep at it however long it takes
1.6. Tetlock’s “Ten Commandments for Aspiring Superforecasters:”
This advice is given at the end of the book, and may make less sense to someone who hasn’t read the book. A full transcript of these commandments can be found here; this is a summary:
(1) Triage: Don’t waste time on questions that are “clocklike” where a rule of thumb can get you pretty close to the correct answer, or “cloudlike” where even fancy models can’t beat a dart-throwing chimp.
(2) Break seemingly intractable problems into tractable sub-problems: This is how Fermi estimation works. One related piece of advice is “be wary of accidentally substituting an easy question for a hard one,” e.g. substituting “Would Israel be willing to assassinate Yasser Arafat?” for “Will at least one of the tests for polonium in Arafat’s body turn up positive?”
(3) Strike the right balance between inside and outside views: In particular, first anchor with the outside view and then adjust using the inside view.
(4) Strike the right balance between under- and overreacting to evidence: Usually do many small updates, but occasionally do big updates when the situation calls for it. Remember to think about P(E|H)/P(E|~H); remember to avoid the base-rate fallacy. “Superforecasters aren’t perfect Bayesian predictors but they are much better than most of us.” 16
(5) Look for the clashing causal forces at work in each problem: This is the “dragonfly eye perspective,” which is where you attempt to do a sort of mental wisdom of the crowds: Have tons of different causal models and aggregate their judgments. Use “Devil’s advocate” reasoning. If you think that P, try hard to convince yourself that not-P. You should find yourself saying “On the one hand… on the other hand… on the third hand…” a lot.
(6) Strive to distinguish as many degrees of doubt as the problem permits but no more.
(7) Strike the right balance between under- and overconfidence, between prudence and decisiveness.
(8) Look for the errors behind your mistakes but beware of rearview-mirror hindsight biases.
(9) Bring out the best in others and let others bring out the best in you. The book spent a whole chapter on this, using the Wehrmacht as an extended case study on good team organization. One pervasive guiding principle is “Don’t tell people how to do things; tell them what you want accomplished, and they’ll surprise you with their ingenuity in doing it.” The other pervasive guiding principle is “Cultivate a culture in which people—even subordinates—are encouraged to dissent and give counterarguments.” 17
(10) Master the error-balancing bicycle: This one should have been called practice, practice, practice. Tetlock says that reading the news and generating probabilities isn’t enough; you need to actually score your predictions so that you know how wrong you were.
(11) Don’t treat commandments as commandments: Tetlock’s point here is simply that you should use your judgment about whether to follow a commandment or not; sometimes they should be overridden.
1.7. Recipe for Making Predictions
Tetlock describes how superforecasters go about making their predictions. 18 Here is an attempt at a summary:
- Sometimes a question can be answered more rigorously if it is first “Fermi-ized,” i.e. broken down into sub-questions for which more rigorous methods can be applied.
- Next, use the outside view on the sub-questions (and/or the main question, if possible). You may then adjust your estimates using other considerations (‘the inside view’), but do this cautiously.
- Seek out other perspectives, both on the sub-questions and on how to Fermi-ize the main question. You can also generate other perspectives yourself.
- Repeat steps 1 – 3 until you hit diminishing returns.
- Your final prediction should be based on an aggregation of various models, reference classes, other experts, etc.
1.8. Bayesian reasoning & precise probabilistic forecasts
Humans normally express uncertainty with terms like “maybe” and “almost certainly” and “a significant chance.” Tetlock advocates for thinking and speaking in probabilities instead. He recounts many anecdotes of misunderstandings that might have been avoided this way. For example:
In 1961, when the CIA was planning to topple the Castro government by landing a small army of Cuban expatriates at the Bay of Pigs, President John F. Kennedy turned to the military for an unbiased assessment. The Joint Chiefs of Staff concluded that the plan had a “fair chance” of success. The man who wrote the words “fair chance” later said he had in mind odds of 3 to 1 against success. But Kennedy was never told precisely what “fair chance” meant and, not unreasonably, he took it to be a much more positive assessment. 19
This example hints at another advantage of probabilistic judgments: It’s harder to weasel out of them afterwards, and therefore easier to keep score. Keeping score is crucial for getting feedback from reality, which is crucial for building up expertise.
A standard criticism of using probabilities is that they merely conceal uncertainty rather than quantify it—after all, the numbers you pick are themselves guesses. This may be true for people who haven’t practiced much, but it isn’t true for superforecasters, who are impressively well-calibrated and whose accuracy scores decrease when you round their predictions to the nearest 0.05. (EDIT: This should be 0.1)20
Bayesian reasoning is a natural next step once you are thinking and talking probabilities—it is the theoretical ideal in several important ways 21 —and Tetlock’s experience and interviews with superforecasters seems to bear this out. Superforecasters seem to do many small updates, with occasional big updates, just as Bayesianism would predict. They recommend thinking in the Bayesian way, and often explicitly make Bayesian calculations. They are good at breaking down difficult questions into more manageable parts and chaining the probabilities together properly.
2. Discussion: Relevance to AI Forecasting
2.1. Limitations
A major limitation is that the forecasts were mainly on geopolitical events only a few years in the future at most. (Uncertain geopolitical events seem to be somewhat predictable up to two years out but much more difficult to predict five years out.) 22 So evidence from the GJP may not generalize to forecasting other types of events (e.g. technological progress and social consequences) or events further in the future.
That said, the forecasting best practices discovered by this research are not overtly specific to geopolitics or near-term events. Also, geopolitical questions are diverse and accuracy on some was highly correlated with accuracy on others. 23
Tetlock has ideas for how to handle longer-term, nebulous questions. He calls it “Bayesian Question Clustering.” (Superforecasting 263) The idea is to take the question you really want to answer and look for more precise questions that are evidentially relevant to the question you care about. Tetlock intends to test the effectiveness of this idea in future research.
2.2 Value
The benefits of following these best practices (including identifying and aggregating the best forecasters) appear to be substantial: Superforecasters predicting events 300 days in the future were more accurate than regular forecasters predicting events 100 days in the future, and the GJP did even better. 24 If these benefits generalize beyond the short-term and beyond geopolitics—e.g. to long-term technological and societal development—then this research is highly useful to almost everyone. Even if the benefits do not generalize beyond the near-term, these best practices may still be well worth adopting. For example, it would be extremely useful to have 300 days of warning before strategically important AI milestones are reached, rather than 100.
3. Contributions
Research, analysis, and writing were done by Daniel Kokotajlo. Katja Grace and Justis Mills contributed feedback and editing. Tegan McCaslin, Carl Shulman, and Jacob Lagerros contributed feedback.
4. Footnotes
- The table is from Mellers et al 2015. “Del time” is deliberation time.
- “Nonetheless, as we saw in the structural model, and confirm here, the best model uses dispositional, situational, and behavioral variables. The combination produced a multiple correlation of .64.” This is from Mellers et al 2015.
- This is from Mellers et al 2015.
- On the webpage, it says forecasters with better track-records and those who update more frequently get weighted more. In these slides, Tetlock describes the elitism differently: He says it gives weight to higher-IQ, more open-minded forecasters.
- According to one expert I interviewed, more recent data suggests that the successes of the extremizing algorithm during the forecasting tournament were a fluke. After all, a priori one would expect extremizing to lead to small improvements in accuracy most of the time, but big losses in accuracy some of the time.
- This is from this seminar.
- For example, in year 2 one superforecaster beat the extremizing algorithm. More generally, as discussed in this seminar, the aggregation algorithm produces the greatest improvement with ordinary forecasters; the superforecasters were good enough that it didn’t help much.
- This is from Chang et al 2016. The average brier score of answers tagged “comparison classes” was 0.17, while the next-best tag averaged 0.26.
- There is experimental evidence that superforecasters are less prone to standard cognitive science biases than ordinary people. From edge.org: Mellers: “We have given them lots of Kahneman and Tversky-like problems to see if they fall prey to the same sorts of biases and errors. The answer is sort of, some of them do, but not as many. It’s not nearly as frequent as you see with the rest of us ordinary mortals. The other thing that’s interesting is they don’t make the kinds of mistakes that regular people make instead of the right answer. They do something that’s a little bit more thoughtful. They integrate base rates with case-specific information a little bit more.”
- The superforecasters had a calibration of 0.01, which means that the average difference between a probability they use and the true frequency of occurrence is 0.01. This is from Mellers et al 2015. The fact about rounding their predictions is from Friedman et al 2018. EDIT: Seems I was wrong, thanks to this commenter for noticing.https://www.metaculus.com/questions/4166/the-lightning-round-tournament-comparing-metaculus-forecasters-to-infectious-disease-experts/#comment-28756
- For an excellent introduction to Bayesian reasoning and its theoretical foundations, see Strevens’ textbook-like lecture notes. Some of the facts summarized in this paragraph about Superforecasters and Bayesianism can be found on pages 169-172, 281, and 314 of Superforecasting.
- Tetlock admits that “there is no evidence that geopolitical or economic forecasters can predict anything ten years out beyond the excruciatingly obvious… These limits on predictability are the predictable results of the butterfly dynamics of nonlinear systems. In my EPJ research, the accuracy of expert predictions declined toward chance five years out.” (Superforecasting p243)
- “There are several ways to look for individual consistency across questions. We sorted questions on the basis of response format (binary, multinomial, conditional, ordered), region (Eurzone, Latin America, China, etc.), and duration of question (short, medium, and long). We computed accuracy scores for each individual on each variable within each set (e.g., binary, multinomial, conditional, and ordered) and then constructed correlation matrices. For all three question types, correlations were positive… Then we conducted factor analyses. For each question type, a large proportion of the variance was captured by a single factor, consistent with the hypothesis that one underlying dimension was necessary to capture correlations among response formats, regions, and question duration.” From Mellers et al 2015.
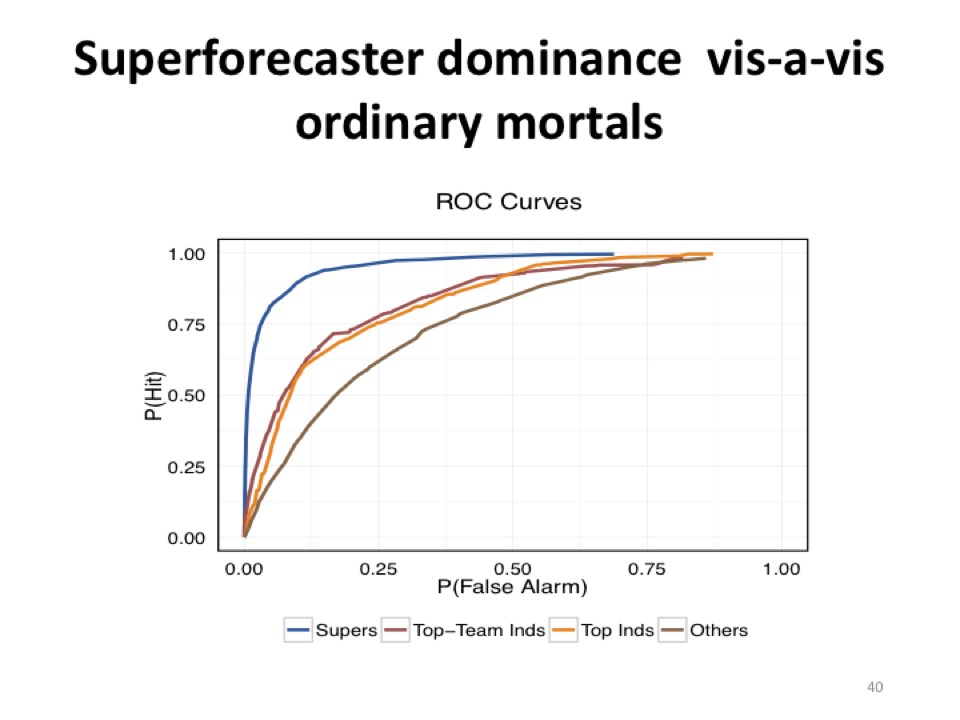
- Superforecasting p94. Later, in the edge.org seminar, Tetlock says “In some other ROC curves—receiver operator characteristic curves, from signal detection theory—that Mark Steyvers at UCSD constructed—superforecasters could assign probabilities 400 days out about as well as regular people could about eighty days out.” The quote is accompanied by a graph; unfortunately, it’s hard to interpret.
{kind=link}
