uncategorized:capabilities_of_sota_ai
This is an old revision of the document!
Table of Contents
Capabilities of state-of-the-art AI, 2023
This is a list of some noteworthy capabilities of current state-of-the-art AI in various categories. Last updated 2/27/2023.
Games
- In 2017, AlphaZero learned to play Chess, Shogi, and Go better than the best human players after less than 8 hours of training each, starting with no domain knowledge or examples of human play.1)
- In 2020, MuZero also learned to play Chess, Shogi, and Go better than the best human players with no domain knowledge or examples of human play, and additionally without initially knowing the rules of the games.2)
- In 2020, Agent57 learned to play all 57 Atari games above average human level.3)
- In 2021, EfficientZero, a variation of MuZero, learned to play 26 Atari games at 109% of median human performance after only 2 hours of gameplay.4)
- In 2019, Pluribus won a game of Texas Hold’Em against 5 professional poker players. Pluribus was trained using self-play, starting with no human data or domain knowledge, and using the equivalent of $150 in compute.5)
- In 2019, OpenAI Five defeated a professional Dota 2 team twice in 2019.6)
- In 2019, OpenAI Five defeated 99.4% of Dota 2 players in public matches.7)
- In 2019, AlphaStar reached Grandmaster level in Starcraft, playing with the same constraints as a human player (viewing the world through a camera, restricted clickrate).8)
- DreamerV3 is a general algorithm from 2023 that can learn to play a variety of games without human data, and is able to collect diamonds in Minecraft.9)
- CICERO, from 2022, can play Diplomacy, a game that involves communicating and coordinating with other players. Cicero ranked in the top 10% of players who had played more than one game on webDiplomacy.net.10)
- In 2022, DeepNash won 84% of Stratego games against the top expert human players on Gravon games.11)
Language
- ChatGPT is a chatbot from 2022, trained on GPT-3.5. It can write poetry, act out characters, answer questions, and more.12)

- LaMDA is a chatbot from 2022 that was evaluated by human crowdworkers to score 92.9% for “sensibleness” (compared to 100% for human crowdoworker-generated dialogue), 79% for “specificity” (compared to 80% for human crowdworker-generated dialogue), and 25.7% for “interestingness” (compared to 19% for human crowdworker-generated dialogue, although the authors note that the human crowdworkers may have not been trying to write interesting dialogue).13)

- PaLM, a language model from 2022, surpassed average human performance on BIG-bench, “a collaborative benchmark aimed at producing challenging tasks for large language models.”14)
- PaLM correctly answered 58% of the questions in GMS8K, a dataset of elementary school level math word problems.12
- PaLM-Coder wrote code that correctly solved programming problems in the HumanEval dataset 36% of the time. When given 100 tries for each problem, the model solved them 88.4% of the time.12
- PaLM-Coder successfully repaired 82.1% of the broken code in the DeepFix dataset.12
- PaLM-Coder successfully translated 55.1% of C++ programs in the Transcoder dataset to Python.12
- As of 2020, Google Translate supported over 100 languages. When translating from other languages into English, its translations received BLEU scores ranging from around 0.15 to 0.53, depending on the language. BLEU score is based on the similarity of a translation to one created by a human translator, and ranges from 0 to 1, where a score of 1 indicates output identical to a human translator.15)
- Elicit is an AI research assistant from 2022 that, given a research question, can find relevant papers and summarize the findings of the top four papers.16)
- In 2022, Ithaca restored the missing text in ancient Greek inscriptions with 62% accuracy.17)
Images
- DenseCap can identify and describe objects in an image.18)
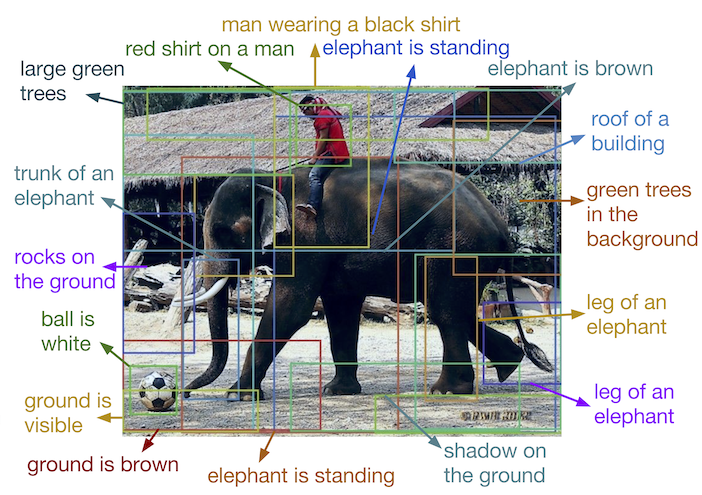
- Sensetime is a facial recognition system from 2014 that surpassed average human performance in accurately labeling faces in a large dataset of images.19)
- LipNet is a lip-reading system from 2016 that reached superhuman performance in lip-reading.20)
- AI systems created by Google have reached human-level performance in some tasks related to analyzing medical imaging.21)
- CLIP, from 2021, can create a text description of an image.22)
- DALL-E 2, from 2022, can create images from text descriptions.23)

- Muse can also generate images from text descriptions, more efficiently than other models such as DALL-E 2.24)
- DeepFaceLab, from 2020, can swap a face in a video with another person’s face (“deepfakes”).25)
- Generative adversarial networks such as StyleGAN2, from 2019, can be trained to create realistic images of something within a certain category, such as human faces.26)

Audio
- Many models can read text with a human-like voice. Tacotron 2, from 2017, generated voice samples that received a mean opinion score of 4.53/5 compared to 4.58/5 for professionally recorded human speech.27)
- Automatic speech recognition systems can transcribe recordings of human speech. Whisper, from 2022, is able to transcribe recordings with an accuracy close to that of professional human transcribers.28)
- Jukebox, from 2020, can generate samples of music with a provided genre, artist, and lyrics as input.29)
- AudioLM, from 2022, creates predicted “continuations” of an audio input.30)
- MusicLM, from 2022, creates samples of music based on a text caption.31)
- Models such as Deep Voice 3, from 2018, can imitate a human voice based on a few samples of recorded speech.32)
- Recent models such as Koe can take a recorded voice sample and change it into another voice.33)
Robotics
- Although they are prone to occasional mistakes, self-driving cars are able to drive with human supervision.34)
- In 2021, an AI-piloted drone won a race against drones piloted by human experts.35)
- Atlas, a humanoid robot, can walk, run, and perform parkour moves such as backflips.36)
- A robot made by OpenAI in 2019 can solve a rubik’s cube with one human-like hand.37)
- In 2022, a robot successfully performed laparoscopic surgery on four pigs, without human assistance.38)
Biology
- Given a sequence of amino acids, AlphaFold 2, from 2022, can predict a 3d model of the protein that they make up.39) In CASP14 (Critical Assessment of Structure Prediction), AlphaFold 2’s predicted structures had a “median backbone accuracy of 0.96 Å r.m.s.d.95 (Cα root-mean-square deviation at 95% residue coverage) (95% confidence interval = 0.85–1.16 Å).”40)
- In 2022 a model was able to predict the effect of a molecule on levels of an enzyme in humans and find molecules that inhibit a particular enzyme.41)
- MinD-Vis, from 2022, can decode a subject’s brain activity to reconstruct an image that has some of the details and features of the image the subject is looking at.42)
1)
Silver, D., Hubert, T., Schrittwieser, J., Antonoglou, I., Lai, M., Guez, A., Lanctot, M., Sifre, L., Kumaran, D., Graepel, T., Lillicrap, T., Simonyan, K., & Hassabis, D. (2017). Mastering Chess and Shogi by Self-Play with a General Reinforcement Learning Algorithm. arXiv. https://doi.org/10.48550/arXiv.1712.01815
2)
Schrittwieser, J., Antonoglou, I., Hubert, T., Simonyan, K., Sifre, L., Schmitt, S., Guez, A., Lockhart, E., Hassabis, D., Graepel, T., Lillicrap, T., & Silver, D. (2019). Mastering Atari, Go, Chess and Shogi by Planning with a Learned Model. arXiv. https://doi.org/10.1038/s41586-020-03051-4
3)
Badia, A. P., Piot, B., Kapturowski, S., Sprechmann, P., Vitvitskyi, A., Guo, D., & Blundell, C. (2020). Agent57: Outperforming the Atari Human Benchmark. arXiv. https://doi.org/10.48550/arXiv.2003.13350
4)
Ye, W., Liu, S., Kurutach, T., Abbeel, P., & Gao, Y. (2021). Mastering Atari Games with Limited Data. arXiv. https://doi.org/10.48550/arXiv.2111.00210
5)
Facebook, Carnegie Mellon build first AI that beats pros in 6-player poker. Meta AI. (2019, July 11). Retrieved November 22, 2022, from https://ai.facebook.com/blog/pluribus-first-ai-to-beat-pros-in-6-player-poker
6)
Wiggers, K. (2019, April 13). Openai five defeats professional dota 2 team, twice. VentureBeat. Retrieved November 22, 2022, from https://venturebeat.com/ai/openai-five-defeats-a-team-of-professional-dota-2-players
7)
Wiggers, K. (2019, April 22). OpenAI's Dota 2 bot defeated 99.4% of players in public matches. VentureBeat. Retrieved November 22, 2022, from https://venturebeat.com/ai/openais-dota-2-bot-defeated-99-4-of-players-in-public-matches
8)
Alphastar: Grandmaster level in starcraft II using multi-agent reinforcement learning. DeepMind. (2019, October 30). Retrieved November 22, 2022, from https://www.deepmind.com/blog/alphastar-grandmaster-level-in-starcraft-ii-using-multi-agent-reinforcement-learning
9)
Hafner, D., Pasukonis, J., Ba, J., & Lillicrap, T. (2023). Mastering Diverse Domains through World Models. arXiv. https://doi.org/10.48550/arXiv.2301.04104
10)
Cicero. Meta AI. (n.d.). Retrieved November 23, 2022, from https://ai.facebook.com/research/cicero
11)
Mastering Stratego, the Classic Game of Imperfect Information. DeepMind blog. (2022, December 1). Retrieved December 2, 2022, from https://www.deepmind.com/blog/mastering-stratego-the-classic-game-of-imperfect-information
12)
Introducing ChatGPT. (n.d.). OpenAI. Retrieved March 8, 2023, from https://openai.com/blog/chatgpt
13)
Thoppilan, R., De Freitas, D., Hall, J., Shazeer, N., Kulshreshtha, A., Cheng, H., Jin, A., Bos, T., Baker, L., Du, Y., Li, Y., Lee, H., Zheng, H. S., Ghafouri, A., Menegali, M., Huang, Y., Krikun, M., Lepikhin, D., Qin, J., . . . Le, Q. (2022). LaMDA: Language Models for Dialog Applications. arXiv. https://doi.org/10.48550/arXiv.2201.08239
14)
Chowdhery, A., Narang, S., Devlin, J., Bosma, M., Mishra, G., Roberts, A., Barham, P., Chung, H. W., Sutton, C., Gehrmann, S., Schuh, P., Shi, K., Tsvyashchenko, S., Maynez, J., Rao, A., Barnes, P., Tay, Y., Shazeer, N., Prabhakaran, V., . . . Fiedel, N. (2022). PaLM: Scaling Language Modeling with Pathways. arXiv. https://doi.org/10.48550/arXiv.2204.02311
15)
Caswell, I., & Liang, B. (2020, June 8). Recent advances in Google Translate. Google AI Blog. Retrieved November 22, 2022, from https://ai.googleblog.com/2020/06/recent-advances-in-google-translate.html
16)
Elicit FAQ. Elicit.org. (2022, April). Retrieved November 22, 2022, from https://elicit.org/faq
17)
Assael, Y., Sommerschield, T., Shillingford, B., Bordbar, M., Pavlopoulos, J., Chatzipanagiotou, M., Androutsopoulos, I., Prag, J., & de Freitas, N. (2022). Restoring and attributing ancient texts using deep neural networks. Nature, 603(7900), 280–283. https://doi.org/10.1038/s41586-022-04448-z
18)
Johnson, J., & Karpathy, A. (2015). DenseCap: Fully Convolutional Localization Networks for Dense Captioning. arXiv. https://doi.org/10.48550/arXiv.1511.07571
19)
Lu, C., & Tang, X. (2014). Surpassing Human-Level Face Verification Performance on LFW with GaussianFace. arXiv. https://doi.org/10.48550/arXiv.1404.3840
20)
Assael, Y. M., Shillingford, B., Whiteson, S., & de Freitas, N. (2016). LipNet: End-to-End Sentence-level Lipreading. arXiv. https://doi.org/10.48550/arXiv.1611.01599
21)
AI Imaging & Diagnostics. Google Health. (n.d.). Retrieved November 22, 2022, from https://health.google/health-research/imaging-and-diagnostics/
22)
Radford, A., Kim, J. W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., Krueger, G., & Sutskever, I. (2021). Learning Transferable Visual Models From Natural Language Supervision. arXiv. https://doi.org/10.48550/arXiv.2103.00020
23)
OpenAI. (2022, April 14). Dall·E 2. OpenAI. Retrieved November 22, 2022, from https://openai.com/dall-e-2
24)
Muse: Text-To-Image Generation via Masked Generative Transformers, https://muse-model.github.io/ . Accessed 9 January 2023.
25)
Perov, I., Gao, D., Chervoniy, N., Liu, K., Marangonda, S., Umé, C., Dpfks, M., Facenheim, C. S., RP, L., Jiang, J., Zhang, S., Wu, P., Zhou, B., & Zhang, W. (2020). DeepFaceLab: Integrated, flexible and extensible face-swapping framework. arXiv. https://doi.org/10.48550/arXiv.2005.05535
26)
Karras, T., Laine, S., Aittala, M., Hellsten, J., Lehtinen, J., & Aila, T. (2019). Analyzing and Improving the Image Quality of StyleGAN. ArXiv. https://doi.org/10.48550/arXiv.1912.04958
27)
Shen, J., & Pang, R. (2017, December 19). Tacotron 2: Generating human-like speech from text. Google AI Blog. Retrieved November 23, 2022, from https://ai.googleblog.com/2017/12/tacotron-2-generating-human-like-speech.html
28)
Radford, A., Kim, J. W., Xu, T., Brockman, G., McLeavey, C., & Sutskever, I. (2022). Robust Speech Recognition via Large-Scale Weak Supervision. Retrieved November 22, 2022, from https://cdn.openai.com/papers/whisper.pdf
29)
Dhariwal, P., Jun, H., Payne, C., Kim, J. W., Radford, A., & Sutskever, I. (2020). Jukebox: A Generative Model for Music. arXiv. https://doi.org/10.48550/arXiv.2005.00341
30)
AudioLM. Retrieved February 27, 2023, from https://google-research.github.io/seanet/audiolm/examples/
31)
MusicLM: Generating Music From Text. Retrieved February 27, 2023, from https://google-research.github.io/seanet/musiclm/examples/
32)
Arik, S. O., Chen, J., Peng, K., Ping, W., & Zhou, Y. (2018). Neural Voice Cloning with a Few Samples. arXiv. https://doi.org/10.48550/arXiv.1802.06006
33)
Koe: Recast. Koe AI. (n.d.). Retrieved November 22, 2022, from https://koe.ai/recast
34)
Metz, C., Laffin, B., & Thi, H. D. (2022, November 15). What riding in a self-driving Tesla tells us about the future of autonomy. The New York Times. Retrieved November 22, 2022, from https://www.nytimes.com/interactive/2022/11/14/technology/tesla-self-driving-flaws.html
35)
Hambling, D. (2021, July 23). An AI-controlled drone racer has beaten human pilots for the first time. Forbes. Retrieved November 22, 2022, from https://www.forbes.com/sites/davidhambling/2021/07/23/swiss-ai-drone-racer-is-faster-than-human-pilots/?sh=48366e011ea0
36)
Atlas™. Boston Dynamics. (n.d.). Retrieved November 22, 2022, from https://www.bostondynamics.com/atlas
37)
Akkaya, I., Andrychowicz, M., Chociej, M., Litwin, M., McGrew, B., Petron, A., Paino, A., Plappert, M., Powell, G., Ribas, R., Schneider, J., Tezak, N., Tworek, J., Welinder, P., Weng, L., Yuan, Q., Zaremba, W., & Zhang, L. (2019). Solving Rubik's Cube with a Robot Hand. arXiv. https://doi.org/10.48550/arXiv.1910.07113
38)
Gregory, A. (2022, January 26). Robot successfully performs keyhole surgery on pigs without human help. The Guardian. Retrieved November 22, 2022, from https://www.theguardian.com/technology/2022/jan/26/robot-successfully-performs-keyhole-surgery-on-pigs-without-human-help
39)
Alphafold. DeepMind. (n.d.). Retrieved November 22, 2022, from https://www.deepmind.com/research/highlighted-research/alphafold
40)
Jumper, J., Evans, R., Pritzel, A., Green, T., Figurnov, M., Ronneberger, O., Tunyasuvunakool, K., Bates, R., Žídek, A., Potapenko, A., Bridgland, A., Meyer, C., Kohl, S. A., Ballard, A. J., Cowie, A., Romera-Paredes, B., Nikolov, S., Jain, R., Adler, J., … Hassabis, D. (2021). Highly accurate protein structure prediction with alphafold. Nature, 596(7873), 583–589. https://doi.org/10.1038/s41586-021-03819-2
41)
Urbina, F., Lentzos, F., Invernizzi, C., & Ekins, S. (2022). Dual use of artificial-intelligence-powered drug discovery. Nature Machine Intelligence, 4(3), 189–191. https://doi.org/10.1038/s42256-022-00465-9
42)
Seeing beyond the brain: Conditional diffusion model with sparse masked modeling for vision decoding submitted to Anonymous Conference. MinD-Vis. (n.d.). Retrieved November 22, 2022, from https://mind-vis.github.io
uncategorized/capabilities_of_sota_ai.1678315791.txt.gz · Last modified: 2023/03/08 22:49 by harlanstewart
Except where otherwise noted, content on this wiki is licensed under the following license: CC0 1.0 Universal
